You can find algorithms or technologies we used and found worthy to show to you.
May 23th, 2013
After you look around you find tens of seemingly useful chart controls. Most of them have quite a lot of features you might even use. Some of them claims to be fast and a few of them will say they can handle big data.
They are all wrong! If you actually want to see ALL data you will find zero that works. Some will aggregate (calculate average for example) data for you so you can "see" them better. But if the data happen to be that you must see min and max values even while zoomed out they all fail.
We have a chart control that can handle this situation perfectly. We also aggregate data (obviously you cannot draw millions of lines) but not into a single value. Our aggregated data has a min, a max, a left and a right joint. The algorithm then goes like this: for each aggregate draw a vertical line between min and max, then connect right joint with left joint of next aggregate. Usually this leads to vertical lines all over the chart but that is what you want when zoomed out to see a whole year with millions of data. You will see that one value that stands out among the others.
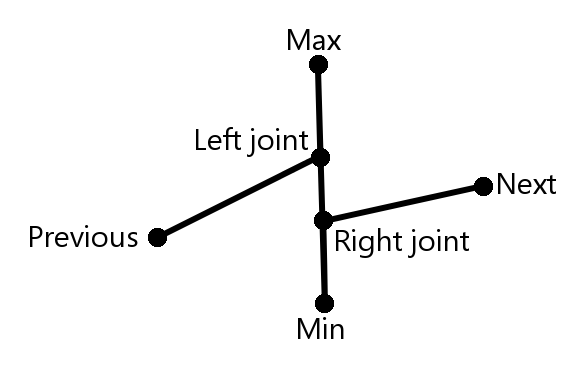
Simple but effective. No data is lost no matter what zoom you are in.
November 30th, 2012
Inserting records on the scale of 100+ millions into a database is slow. For the sake of simplicity let our table be simple: time, name, value. Our querry will always be based on time range so we create an index on time. So far so good. Now try to insert a new record into the database when it already has 100 000 000 rows. Not fast. Not at all. Depends on configuration this can take up to 1 to 10 seconds. Note that without index on column it would be fast. Our system generates 100-1000 records each second (this is the reason we have 100 million rows already in the first place) so how can we address this issue.
Since this was a very special table where you cannot delete or update records (series of time stamped values) we decided to remove the table from the database and store it in files. We designed an indexing algorithm for this that uses hierarchical cache system. Also we compressed data down to 1 byte per record (string table compression combined with delta compression for time and value). Now our system can look up one record with 3 file accesses worst case but usually it is one only since 0th level index is in memory after first access. Range query might open more files as we read all the data needed which is 1000-10000 records per file per name. Query one million records might open 100-1000 files. On our server with a simple SSD on board it takes 10-100 milliseconds to get a result set on the scale of one million.
No more slow insert and select! (given you have a special data structure)